Issue 2, 2014 |
Download pdf |
Scaling the task engine with webMethods 9.7
webMethods BPMS will introduce significant performance enhancements to the task engine with the October 2014 release of webMethods 9.7. Enhancements will include the adoption of Universal Messaging and Terracotta (both Software AG in-memory data management products) as well as support for high-performance third-party data stores such as Hadoop®, CouchDB and others.
Who needs a high-performance task engine?
This is a very exciting time for webMethods BPMS, especially for the task engine component of BPMS. We’ve not only reached a critical mass of successful deployments, but we’re also seeing a huge jump in the number of upcoming BPMS applications as well as a leap in the size of these applications. As a result, webMethods R&D is investing in numerous areas to ensure our customers can succeed with deployment sizes of 12,000+ active concurrent users. This article explores some of the changes in the October 2014 release and how those changes will enable an order of magnitude increase in performance and scalability, including:
- Horizontal scalability improvements using webMethods Universal Messaging
- High-performance task searches using a variety of new components, including Terracotta
Horizontal scalability
Task Engine 9.7 will overcome the horizontal scalability limitations of past versions, specifically increasing the maximum number of task engine nodes that can be deployed to a cluster. In Task Engine 9.6, the maximum number of nodes normally recommended is eight, although the system can continue to scale up to around 12 nodes. (The maximum number of nodes may vary by plus or minus one or two, depending on which features are used, the usage patterns of task engine and other factors, such as memory and CPU.) Unfortunately, at this maximum point, the task engine becomes constrained due to its clustering technology. To understand why the task engine has this limitation, we need to look at the task engine container: My webMethods Server (MWS).
Temporary implementation of Java® Message Service (JMS)
To accommodate numerous high-priority changes required to support the new webMethods BPMS platform, MWS 7.0 was released with a limited internal messaging capability to support new requirements for the MWS cluster technology. Integrated support with task development and deployment, task engine communication with the process engine and other task features were a higher priority than adopting a full JMS implementation at that time.
The limited messaging implementation, a temporary solution, is the primary bottleneck for the horizontal scalability of the current task engine. Figure 1 shows the results of a task engine performance test in which the MWS performance service reports that JMS SQL calls dominate all other RDBMS activity.
The percentage of database traffic caused by the interim solution isn’t constant. In fact, it grows exponentially with the increased numbers of MWS nodes in a cluster. A recent experiment with 24 MWS cluster nodes sitting idle (no user traffic at all) generated more than 2 billion RDBMS calls within two hours, and of course this traffic was mostly the same JMS calls (see Figure 1). Clearly, the temporary JMS implementation needed to be replaced.
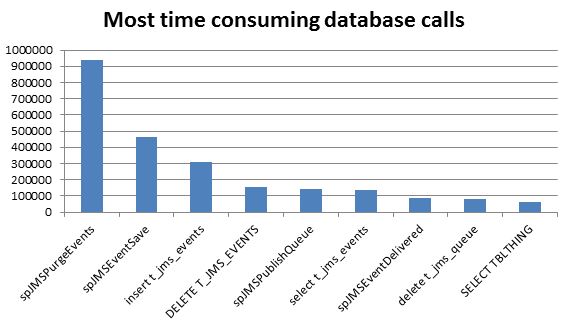
Figure 1: The most expensive database calls (in milliseconds) during a MWS cluster performance test
Universal Messaging
Fortunately, the temporary messaging implementation was designed from the start to be replaced and was developed with strict internal separation. This means adopting a new implementation will not be invasive to the MWS code base, requiring only minimal changes that are mostly to configuration code.
More importantly, Software AG now has its own world-class JMS provider with Universal Messaging. As of the time I’m writing this article, we’ve successfully run a complete regression suite of tests for MWS/Task Engine in a cluster using Universal Messaging. Even better, there were virtually no code changes required other than the expected configuration management. During the remainder of our October 2014 development cycle, we will continue to test our Universal Messaging-based JMS implementation.
We already observed the following benefits of Universal Messaging for MWS JMS:
- For an average cluster, two-thirds of all SQL calls will be eliminated
- For clusters over 12 nodes, there will not be an explosion of JMS-related SQL calls
- The resulting pressure on the RDBMS will be significantly reduced, which should result in measurable improvements for normal task engine calls to the database
- The time to transport events over Universal Messaging is measured as a tiny fraction of the current messaging implementation
Task searches
High-performance task search has always been a driving goal for the task engine and, as a result, we’ve been making consistent progress to improve performance. With Task Engine 8.2, we introduced indexed task searches, which not only enabled fast database optimized searches but also helped minimize the dependency on the task cache. However, we’ve seen that the indexed task search feature can be further improved to meet the ever-increasing performance requirements of our customers.
High-performance task-search reference architecture
Task Engine 9.7 will deliver an entirely new paradigm for creating high-performance task searches. Instead of offering a one-size-fits-all approach, we are creating a reference architecture and implementation you can use as-is or customize to fit your specific needs.
The High Performance Task Search Reference Architecture (HPTSRA) being introduced in October 2014 is comprised of:
- Task events
- Data storage
- Caching layer
- Task search extensions
Each of these components can be customized as required and replaced with one of the supported implementations. For example, the data storage component can be implemented with a traditional RDBMS, Hadoop or CouchDB.

Figure 2: High-performance task-search architectural components
Task events
With the October 2014 release, the task engine will emit an Event-Driven Architecture (EDA) event for every action that occurs during the task life cycle. In previous releases, this would have required the task engine to be configured with “heavyweight” events that were transported over the MWS JMS layer. With the 9.7 release, the task engine will use a lightweight event structure.
To receive these events, you can consume the EDA events using Software AG NERV, or you can create your own mechanism for event handling. A couple of reasonable alternatives that you can implement include publishing the task events over Universal Messaging, or creating an in-process listener to directly handle the task events in the same virtual machine as the task engine.
Task storage
Regardless of how you choose to publish and subscribe to task events, you ultimately want to store the task data that you plan to search in a scalable, high-performance data store. This data store could be a variety of high performance storage components that support scalable searches, such as many of the non-SQL data stores (CouchDB, etc.) or a traditional RDBMS.
As the developer, you will own the choice and configuration of this storage layer and its schema. Part of determining how to get maximum performance from your searches will be determining what type of queries your task application will require. Will you be searching across many task types? Will you be searching across ranges of custom task data? All of your use cases should be accounted for when making the choice of your data store and its schema.
Task search query plug-ins
Now that you’ve listened to task events and stored the task data you want to search, it is time for your users to look at their inboxes (or any other task search results). The HPTSRA will configure the task search content provider to use a query implementation that will search the custom data store instead of the default task schema. This will ensure that if your implementation starts off using the default task searches, it can easily transition to the HPTSRA without requiring re-implementation of the inbox or other custom task searches.
Caching layer
To add finishing touches to the HPTSRA, we are adding a caching layer between the custom task searches and the data store. The reference implementation will leverage Terracotta BigMemory as a caching layer on top of the data store. This adds a small amount of complexity to the storage of data as well as the deployment landscape. It also can add tremendous performance benefits to your searches.
Conclusion
Software AG R&D is working hard to ensure you have the scalability and performance you need to successfully execute large implementations of webMethods BPMS with the task engine and MWS. Task Engine 9.7, coming in October 2014, will greatly improve horizontal scalability with Universal Messaging. And the new HPTSRA will greatly change and improve how you conduct high-performance task searches. I look forward to seeing the adoption of our October 2014 release of task engine and HPTSRA