The remote-data approach, or demystifying the serverSideDataCallback
As pointed out in chapter 1 and chapter 2 of the c8y-data-grid tutorial series, the easiest and potentially dirtiest way to set up a grid is to use the rows attribute. As this doesn’t scale at all if all the data needs to be fetched and held on the client side, we want to use the remote-data approach by setting up a serverSideDataCallback and generating queries whenever the user triggers actions on the grid.
The secret sauce that will drastically improve the performance is the combination of using queries and pagination. That way we will always show data matching the user’s sort and filter criteria, but drastically reduced to just a small dataset being fetched and shown.
The Challenge
The server-side data “mode” requires a lot more effort to be set up and knowledge in many different areas as you need to understand:
- the data source and as such the API you want to query
- the query parameters and/or query language that this API offers
- the abstraction layer of @c8y/client
o how to setup filter objects for list queries
o how to setup query json which is then parsed to a query string byQueriesUtil - how to create own custom filter view components
o how to persist a query in the column
o how to read and translate the query back to be reflected in the filter UI
The Plan

In the following example, we are going to display a list of devices (by using the Inventory API). This implies that we target a Cumulocity IoT Tenant with our queries and can use the query language to our advantage.
You can already check out the example of the remote-data-example from the GitHub repository and follow along while reading the code there.
Our tasks are as follows:
- Wire up the
serverSideDataCallbackproperty - Create queries based on the grid state
Wire up the serverSideDataCallback property

The first task you need to do is to wire up a method that is being bound to the serverSideDataCallback property of the grid. It is recommended to move the logic of that to its own service so that you can reuse that service for different c8y-data-grids.

Inside of your components html (Example)

By using the bind-method, we can bind a method call as if it was a property binding. Make sure to provide and inject that service into your component containing the c8y-data-grid. Now that the serverSideDataCallback is wired up, the method onDataSourceModifier is called, whenever the grid needs to reload. This happens whenever:
- the grid loads for the first time
- the user (re-)sets a filter or sortation
- the user clicks the reload button
- the user changes the current page
The datasourceModifier parameter will then contain the current state of the grid, such as:
- current state of all columns (whether filter or sortation is set)
- searchText (if
showSearchwas set totrueon the grid and the user entered text or cleared the search-field) - pagination information
We will now need to generate queries based on that information. This task will be taken care of by the InventoryDatasourceService on which we call reload (see line 24 of the previous code-example).
As we intend to always just fetch devices, meaning Managed Objects with the c8y_IsDevice fragment, we have a base filter that always needs to be applied. We pass the state of the grid and this base query to the reload method of the InventoryDataSourceService.
These two services are decoupled by intention, as that way you could also create a GroupDataSourceService having the same InventoryDataSourceService as its foundation, just passing a different base-query.
Create queries based on the grid state
Based on the information from the datasourceModifier parameter, we will now need to create 3 queries:

Usually, just one query would be sufficient, which is the query where all filters etc. are considered and the data of the current page would be queried and displayed. Unless you configure the grid to hide its header (by setting the gridHeader property of the grid’s displayOptions to false) and disable pagination (by configuring a load more mode) the grid will show how many items match your current filter/ search and an overall count of items if no filter/ search was applied. This information must be queried too, adding 2 more queries as a result.
We will now have a look at how to implement these 3 queries by starting from the top of the call hierarchy and going down more and more into the details of how this is implemented.
The reload method

Have a look at the implemented reload method:

You can see these 3 queries being declared on lines 21 to 23:
- actual dataset matching the filters (line 21)
- count of dataset matching the filters (line 22)
- count of the dataset without filters (line 23)
Before sending the queries, we first need to create the query strings (lines 18-19). Inside of the fetch calls, these query strings are added as query-attribute to the filter object that is passed to the list-method of the InventoryService. One query (here filterQuery in line 18) will contain the actual query information, while the other query just contains the base query (allQuery in line 19). The results of the queries are then returned combined as ServerSideDataResult which the grid will then consume to update its view.
Next, let’s have a detailed look at the methods fetchManagedObjectsForPage and fetchManagedObjectsCount which are called by the reload method.
The fetch methods: fetchManagedObjectsForPage and fetchManagedObjectsCount
fetchManagedObjectsForPage

(Example)
In the method fetchManagedObjectsForPage we just combine the query string, pagination information (pageSize and currentPage which are destructured from paging) to a filter object that we then pass to the list method.
If you want more information about parent-managed objects, you can set withParents to true. It’s important to set withTotalPages to false as the number of pages is calculated via the fetchManagedObjectsCount calls. Unnecessarily setting withTotalPages to true would drain the performance.
The list method then retrieves and returns all items matching the query parameter for the current page, cut into little chunks depending on the size of the pageSize attribute that was configured in the filter object.
fetchManagedObjectCount

The method fetchManagedObjectCount doesn’t use a count endpoint of the API, but instead also uses the list method, but with adds a little trick: By setting the pageSize to 1 and withTotalPages to true, the totalPages information of the retrieved response matches the count of items in our dataset. The method returns this count wrapped in a Promise (lines 59-61).
Query generation
Now that we have covered how the requests are sent, let’s now dive even deeper and check out how the queries for these requests are generated. Remember – the filterQuery and allQuery strings were the first things we created in the reload method of the InventoryDataSourceService.
The createQueryFilter function

The function createQueryFilter generates a query string based on the information it gets from the columns
-array and the baseQuery parameter. If you want to extend your query also by the search, you could also add it as a third parameter here (by extracting it from the datasourceModifier parameter of the reload method).
The approach is to create a query JSON object which then the QueriesUtil (which is part of @c8y/client) converts to a string. You can find examples of how such query strings look in the OpenAPI documentation. If you need help with how to build the JSON query object, hover over the buildQuery method and check out the comprehensive JSDoc guide there.
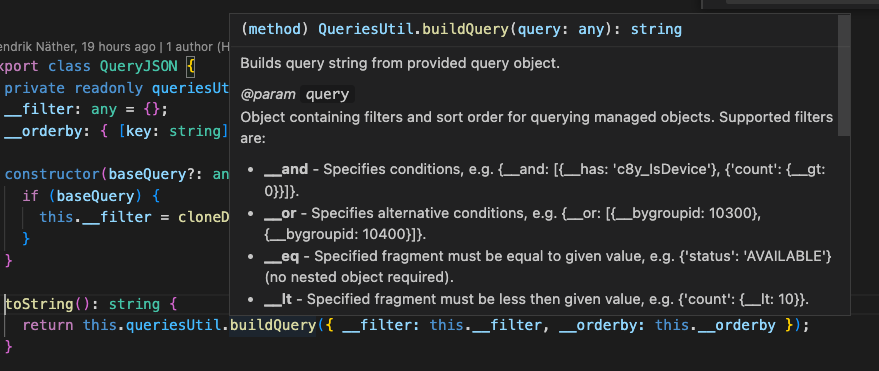
This query string is then used in the filter parameter that is given to the list function of the InventoryService. You could basically also set query strings directly on the filter object in a static way, but in this context, we need to dynamically create it, depending on the state of the columns and whether or not filters or sortations are set or not.
This dynamic part is done in the reduce function, which starts with a very basic JSON structure, containing the __filter attribute with the base query or just an empty object. As previously mentioned – the grid supports sorting multiple columns and this also reflects in the __orderby attribute being initialized with an empty array.
The extendQueryByColumn function
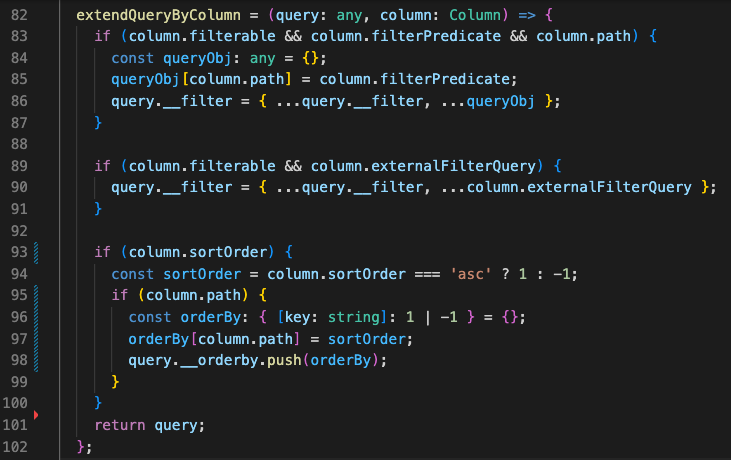
For every column, we extend the queryJSON object in case filter or sortation information is available in the column.
__filter
In case the user has set a standard string filter on a column in the UI, it would implicitly mean that the filterable attribute was set to true for that column and we can expect the filterPredicate to contain a string with the value that the user entered. We convert that to an equals-query by setting the path as key and the filterPredicate-content as the value (line 86) of __filter.
More complex queries, and especially custom-filter queries, are usually written into the externalFilterQuery attribute of the column. We expect the custom filter view to already set an appropriate query JSON and just extend __filter with whatever is stored in the externalFilterQuery object.
__orderby
Next, we need to check whether a column has been sorted or not. As columns are sortable by default, we do not check for sortable to be true, but instead just check if the sortOrder got set for that column as it changes whenever the user clicks on the sort button.
If a sortOrder was set, and thus the column is sorted ascending or descending, we add a key-value pair to the __orderby array, where the key is the path of the column, and the value is either 1 for ascending or -1 for descending order (line 94).
Done!

That’s it for a basic setup if you want to use the remote-data “mode” of the c8y-data-grid. We have covered how to wire the grid up to a datasource-service, why to use a base-query, and how the InventoryDataSourceService translates the state of the grid’s columns into list queries going against the Cumulocity IoT tenant.

If you want to see the complete code working in action, please check out the open-source project, run it locally and have a look at the remote-data-example.
The result doesn’t look that different from the local data approach, right? But under the hood, we are now using a way more powerful approach that will guarantee good performance even if large datasets are shown.