Using Containers
A container is a lightweight, standalone, executable package of software that includes everything needed to run an application; that is, source code and all dependencies, such as the runtime, system tools, system libraries, and configurations.
Because containers are self-sustained, they ensure that an application is decoupled from any environmental specifics. If a container image gets distributed to developers, every one of them will run the exact same application with all its dependencies. When this image gets promoted to a test or production environment, the technology ensures that it is the same piece of software the developers created and tested on their machines. This holds true regardless of whether those environments are in a local data center, a cloud provider, or a hybrid of the two. Since configurations for resources such as databases, identity providers, or systems hosts vary in different environments, configurations are externalized so they can be passed to the container as part of the promotion process.
Unlike VMs, which include their own operating systems and require a hypervisor to run, containers reuse much of the host operating system, include the minimum run time requirements of the application, and do not require a hypervisor. VMs are full-size virtualized computers that run everything a computer runs, while containers run a single application mapped to a single process; you will never encounter two servers running in the same container. (Note: While many processes can run in containers, it is not considered a good practice.)
One can easily spin up container instances from a container image and just as easily bring them down, as well as deploy container instances quickly, stack many applications on a host, and run the applications simultaneously. Since container instances are designed to run in large numbers, they do not save their state inside the container. As a result, everything that happens during run time that is not preserved outside of the container (for example, in a database or storage) is not retained.
You can use a remote repository to share your container images with others, or you can configure your own private repository. Like a source code repository, the registry can contain different versions of a container image.
Additional Information
Disclaimer
The content of this article is only applicable to the webMethods product suite and does not claim to cover the overall containerization and orchestration story of Software AG as a company.
Using Containers with webMethods Products
All products in the webMethods suite use Docker as its container image creation tooling, but you can use any Open Container Initiative (OCI) compliant tooling. With Docker, you can develop an application in the traditional webMethods way, then package it in a solution image. You can then test this image and promote it to other environments to run as a container without any additional code changes.
Product Images
A product image is a default installation of a single runtime, such as a Microservices Runtime, a Universal Messaging server, or an API Gateway. The product image contains the product and its fixes but does not contain any licenses, configurations, or assets. A product image can be compared to a default installation with the latest fixes.
You can get a pre-build product image with the latest fixes for SoftwareAG’s public container registry - https://containers.softwareag.com. This will ensure that you will always have the latest product version with minimal effort.
Alternatively one could use legacy ways to obtain a product image - from an on-prem installation and out-of-the-box Docker scripts or via Software AG product from the Software AG Installer.
Use Software AG-Provided Product Images from SoftwareAG Public Container Registry
Software AG provides product images on its official organization in SoftwareAG Public Container Registry. The provided images are production ready, officially supported by SoftwareAG and use BYOL(bring your own license) strategy when to be deployed on prod environments.
Each image includes a single product. Microservices Runtime image does not include any layered products.
All images include the latest product fixes and release new versions no longer than a week after an official product fix is available.
This is the default way for SoftwareAG to deliver its products on containers.
Create a Product Image from an On-Prem Installation
You can create a product image with fixes from an on-prem product installation and the out-of-the-box Docker scripts. Follow these steps:
- Install Docker on the target machine.
- Use the Software AG Installer to install a product such as Microservices Runtime on the machine.
- Trigger the Docker creation scripts that come with the product to create a product image.
- Use the Docker CLI to push the image to a container repository.
When you want to update to a new fix level or upgrade to a new Software AG release, you will need to create a new product image.
This process is rather slow and cumbersome, but still viable if you require building a specific flavor of product images.
Summary of how to get product images
| Product | container.softwareag.com | On-prem installation |
|---|---|---|
| MSR/IS | Yes | Yes |
| MSR/IS layered products | No | Yes |
| Universal Messaging | Yes | Yes |
| Terracotta | Yes | Yes |
| API Gateway | Yes | Yes |
| API Microgateway | Yes | Yes |
| Developer Portal | Yes | Yes |
| MyWebMethods | No | Yes |
| MyWebMethods layered products | No | Yes |
Additional Information
Creation of Solution Images
A solution image is the result of a CI/CD build process based on a previously defined product image (product installation with fixes) plus developed assets. This creates a working piece of software that can go through unit and integration tests and eventually be deployed into production.
You can create solution images using the file copy functionality of the Docker multi-stage build process. Below is an example of Microservices Runtime.
- Inject package assets into the solution image by copying the packages to the IntegrationServer/packages directory. When the container starts, it will load the packages onto Microservices Runtime.
Rebuild your solution images after a new product image gets available(with a new fix or a new product version) or whenever you produce new assets. The latter might be as often as daily in active development when using a properly set up CI.
Important! The solution images are ephemeral (immutable) and can be changed only in design time. Starting a container from the image manipulating it with a runtime deployment tool (such as webMethods Deployer) is an anti-pattern and does not leverage the benefits of the container technology.
Configure your solution
As images are immutable, we must be able to promote the same solution image from development to production without changing the application or it’s dependencies.
To achieve this, the application configuration should be fully decoupled from the image itself. Our product supports this by externalizing the configuration through configuration files and environment variables.
Here are some exmpales on how to achieve this with MSR
- Inject configurations by mounting the application.properties template when starting the container from the solution image. Extracting the configuration from the applications allows you to promote the same container to all environments.
- If there are configurations with external dependencies, like Keystore or Truststore certificates, you must mount them when starting the container.
Additional Information
Container Life-cycle Supported by Software AG
If you already use a Software AG Local Development Environment and a version control system such as Git to store your assets and configuration, you must not adapt your development setup when moving toward container deployment.
However, you will need to set up a CI process that creates an immutable solution image out of the product image, the licenses, the latest configurations, and your assets.
The Software AG asset and container life cycle is shown below.

The CD promotion process differs from promotion in on-prem environments. In traditional on-prem development, only the source code is promoted, using webMethods Deployer. In container development, the entire solution container, including the dependencies needed for the application, is promoted via a container registry. When a new version of the solution is created, it results in a new container image that is pushed to the container registry. You can then reference the new container registry when you deploy to an orchestration environment like Kubernetes, Open Shift, or Docker Swarm.
Different environments (for example, dev, test, prod) typically require different configurations for resources such as databases, identity providers, licenses, and so on. In containerization this challenge is handled using these approaches:
- The configurations refer to environment variables, which are set appropriately for each environment.
- The configurations are passed to the container in a runtime configuration file, and the file configures the container on startup. This approach is similar to the variable substitution approach used in webMethods Deployer. For Microservices Runtime, starting with 10.5 plus the latest fix, the configuration file can both change existing configurations in the container and create new configurations.
Orchestration
Orchestration is not a new concept for webMethods. webMethods on-premise installations typically orchestrate multiple products to build a solution. For example:
- A standalone Integration Server working with a database component.
- Multiple Integration Servers clustered over a Terracotta service array and a database.
- A BPMS solution consisting of an Integration Server layered with Process Engine and Monitor, connected to a Universal Messaging and a My webMethods Server with Task Engine, all storing runtime data in a Process Audit database component.
webMethods has been leveraging the power of orchestration for decades because a single product rarely can cover a use case on its own.
Using Kubernetes to Orchestrate Containers
You can combine individual solution containers to build a solution by orchestrating those in the same way on-premise installations are orchestrated and wired like:
- Integration Servers or Microservices Runtimes that use messaging need to be configured to access the Universal Messaging service.
- A Universal Messaging container that requires persistence needs to be configured to use a persistent volume.
- Integrations Servers or Microservices Runtimes that leverage an internal database needs to be configured to connect to a prepared database.
Software AG uses the open-source platform Kubernetes to orchestrate container deployments. With Kubernetes, you can deploy, monitor, scale, and upgrade complete solutions more easily than you can when using on-premise installations because you are orchestrating containers rather than physical machines or VMs. Below are some of the key strengths of container orchestration.
| Feature | Description |
|---|---|
| Storage orchestration | Kubernetes can automatically mount the storage system of your choice, whether from local storage; a public cloud provider such as GCP or AWS; or a network storage system such as NFS, iSCSI, Gluster, Ceph, Cinder, or Flocker. |
| Service discovery and load balancing | Kubernetes gives Pods their own IP addresses and a single DNS name for a set of Pods, and can load-balance across them. You don’t have to modify your application to use an unfamiliar service discovery mechanism. |
| Self-healing | Kubernetes restarts containers that fail, replaces and reschedules containers when nodes die, kills containers that don’t respond to your user-defined health check, and only advertises containers to clients when they are ready to serve. |
| Secret and configuration management | With Kubernetes, you can deploy and update secrets and application configurations without rebuilding your image and without exposing secrets in your stack configuration. |
| Horizontal scaling | With Kubernetes, you can scale your application up and down using a simple command or UI, or you can configure Kubernetes to scale your application automatically based on CPU usage. |
| Automated roll-outs and rollbacks | Kubernetes progressively rolls out changes to your application or its configuration, while monitoring application health to ensure it doesn’t kill all your instances at the same time. If something goes wrong, Kubernetes rolls back the change for you. This enables you to take advantage of a growing ecosystem of deployment solutions. |
Kubernetes Flavors
Hyperscalers such as Amazon, Microsoft, and Google have customized Kubernetes as part of their serverless offerings (for example, Amazon EKS, Azure AKS, and Google GKE). Software AG products that are certified for Kubernetes can run on all flavors certified by the Cloud Native Computing Foundation. However, many of those, such as AKS and EKS, offer custom services like databases, specific network storage, secrets managers, and identity providers. To determine whether a Software AG product can run with specific service components, see System Requirements for Software AG Products .
Additional Information
Deploying a Solution in Kubernetes
A full solution deployed in an orchestrated environment will consist of a set of solution images made available in a container image repository. There are several ways to deploy these images:
- Manually deploy each container by pulling it from a container registry via the kubectl CLI. Provide configuration parameters on the command line. Manually define the replica sets and create services on top of those deployments if they are going to expose internal or external network interfaces. Repeat for every solution image you want to deploy.
- Use Kubernetes manifest files that describe the deployment, networking, scaling and configuration and apply it via the kubectl CLI.
- Install and use the Helm package manager that will deploy and configure multiple images with their configuration onto Kubernetes. Software AG currently provides a limited set of scenarios as Helm charts on GitHub. Download the charts and modify them (for example, to point to custom solution images), and then deploy them into the orchestration environment.
Additional Information
Observability of the Kubernetes Infrastructure
To monitor the health of the Kubernetes cluster itself, or the pods and services that run your application, you can use either the kubectl CLI, the standard Kubernetes dashboard application, or some of the custom UIs delivered with specific Kubernetes flavors. Those built-in mechanisms will report the status of the components that make up your application (for example, ready, started, failed).
Monitoring a Solution in Kubernetes
Every Software AG container provides a REST API that returns metrics for the system at the current moment. The metrics provided by the products are quite similar to the ones provided for Software AG’s Optimize for Infrastructure product. These metrics are “pulled” from the containers by Prometheus and aggregated. Prometheus should be installed in the Kubernetes cluster as an application and set up to pull the data from the solution containers based on the Kubernetes service discovery mechanism. The aggregated data will be stored on a non-volatile storage and can be displayed on a custom Grafana dashboard. Prometheus can also send alerts, based on the rules over the collected metrics. This can help administrators proactively perform actions on the application. The following figure gives a good overview of the monitoring architecture of an orchestrated solution.
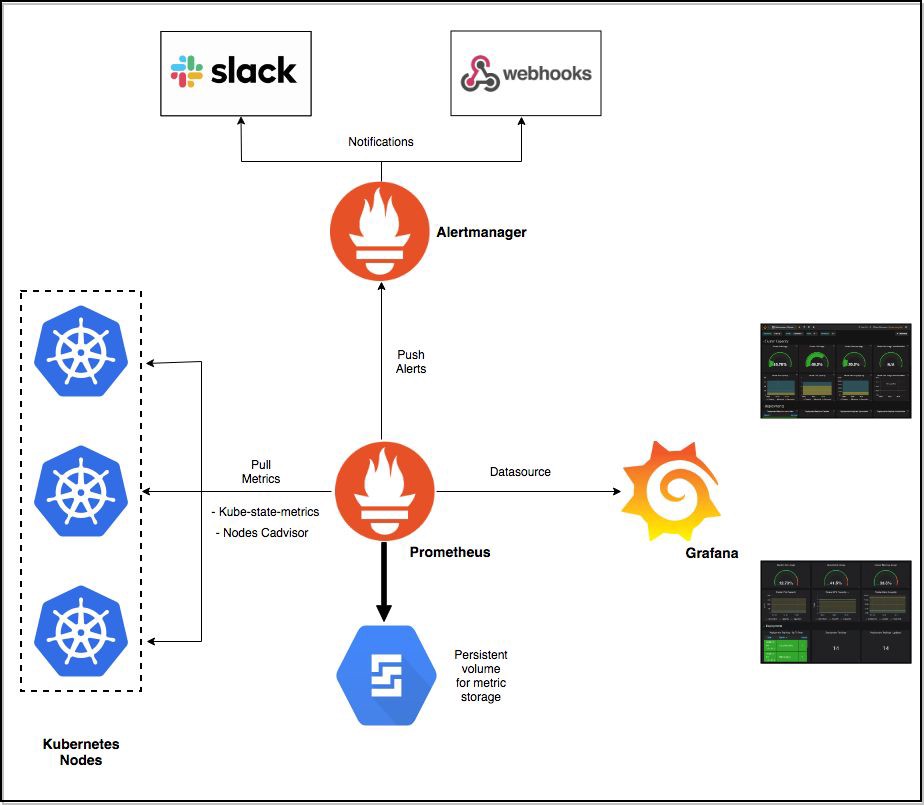
Additional Information
Logging
Logging in containers and orchestration environments differs significantly from the on-premise world. This is due to the ephemeral nature of containers and their scaling capabilities. Logging to a file is not useful because when the container restarts, it just resets the state of the file system and any logging information would be lost, along with the ability to troubleshoot any problem that was present. The scalability of the container means that there isn’t a fixed number of runtimes at a given time, so getting their logs one by one is not a workable solution.
The solution to this is to produce logs only as event streams. The logs from every container should be written to its std.out and std.err streams. This gives other services in an orchestration environment the ability to collect and aggregate those streams for analysis. The pattern is emphasized as factor 11 Logs of the The Twelve Factors App methodology.
The service stack that enables the pattern typically comprises three components: ElasticSearch for persistence, Fluentd to collect the log streams, and Kibana to display and analyze them. This is commonly referred as EFK. Sometimes the stack uses Fluent Bit, which has similar functionality to Fluend but is lighter in size and feature set. A variation may also use Logstash for the log aggregation (ELK). The following diagram gives an overview of the EFK architecture.

To deploy the stack, all components must be downloaded and running in the Kubernetes server. By default, the stack will gather and aggregate all log streams from all solutions. The UI layer, Kibana, can query the logs based on patterns. As the log streams are queried from multiple runtimes and from multiple components, the usage of correlation IDs is highly recommended for troubleshooting.
Backup and Recovery
Similar to the other capabilities discussed above for the orchestration environment, backup and recovery are covered by third-party tools. Those should be installed in the environment to give access to all pods, services and configurations. Possible solutions include Portworx, Velero, OpenEBS, and Rancher Longhorn.
Additional Information
High Availability
High availability is something that comes out of the box with Kubernetes. Every runtime aiming to run in K8s has implemented HTTP endpoints for liveness and readiness. If either does return 200 OK, K8S will automatically restart it and make sure it runs again. The same will happen if there is a Kubernetes node failure. Image the hardware, where your solution was currently running fails; Kubernetes will automatically recognize that one of its nodes are down and will start the containers on different nodes, to make sure they are operational in minimal time.
If the downtime in this scenario does not guarantee the needed SLA, the deployment can be scaled behind a load balancer with more instances. However, this should be allowed by the software itself; for example, Universal Messaging does not allow this in some of its use cases, such as when it is used a JMS provider.
Upgrade
Upgrading a solution in an orchestrated environment is related to updating the underlying images. The images might be updated in the following cases:
- The assets need to be updated (for example, a new Integration Server package, a new Universal Messaging channel or queue).
- A new fix was released for a product.
- A new major release of the product has been deployed.
In any of those cases, a solution image has to be produced via the CI/CD container life cycle described above. The resulting new solution image has to be stored in a container registry that is accessible from the orchestration environment.
When deploying a new solution image to an orchestrated environment, one must consider all dependencies:
- Does the new fix require a fix in another component (for example, an update in the database schema or messaging provider).
- Does the new product version work with the other components in the solution (for example, a product database, Integration Server - Universal Messaging version, or My webMethods Server version).
If the dependencies are satisfied, you can deploy the new image. In certain cases, this deployment will have zero downtime
- Upgrade of stateless application with many replicas
- A typical Microservices Runtime microservice application scenario without a database. The container instances will be gradually replaced by Kubernetes and the requests towards those will be routed to all running pods.
- A Microservices Runtime scenario with messaging. The Microservices Runtimes can be updated one by one and continue to communicate to Universal Messaging.
An upgrade of a stateful application will require downtime. Known limitations are:
- The database has to be separately migrated. Old and new instances of Integration Server and My webMethods Server currently can’t work together against the same version of the db.
- The Universal Messaging storage (data directory) can’t be use simultaneously from different instances as it will become corrupted.
Additional Information
Terminology
| Term | Definition |
|---|---|
| Base image | Operating system for the container, as well as basic tools such as compilers. Can be shared by multiple container images. |
| CI/CD | Continuous integration/ continuous delivery. CI (Continuous Integration) is the process of continuously integrating developed assets into a solution while ensuring their quality. CD (Continuous Delivery) is the process of automatically promoting qualitative assets up to production. |
| Container | Lightweight, standalone, executable package of software that includes everything needed to run an application: the source code and all dependencies, such as the runtime, system tools, system libraries, and settings. Includes a writable layer. |
| Container image | Immutable blueprint for a container runtime. |
| Container instance | Runtime instance of a container. |
| CR | Container registry used to version container images across users and systems. The same image might have multiple versions stored in the CR. |
| Product image | Default installation of a single runtime, such as a Microservices Runtime, a Universal Messaging server, or an API Gateway. The product image contains the product and its fixes but does not contain any licenses, configurations, or assets. A product image can be compared to a default installation with the latest fixes applied. |
| Solution image | Product image to which you have added a layer of licenses, configurations, and assets. |
Product Support for Containers/Kubernetes Deployments
Refer to the latest version of the “System Requirements for Software AG Products” document, sections “Containers” and “Orchestration” on SoftwareAG’s official documentation portal https://documentation.softwareag.com