We can use ChatGPT Connector for intelligent error handling. I have created a workflow to get response from ChatGPT based on query.
Then created a common flow service (intelligentErrorHandling) which takes lastError, input variables and context as input and forms a query. Then it calls that workflow to get response from ChatGPT.
Now this common intelligentErrorHandling flow service can be called from any flow service’s catch block and pass the error , input and context (such as webMethods or webMethods.io MFT etc) . Getting response with the
- proper error message
- possible ways to correct it.
- It also suggests if any blog/posts/forums article with similar error based on the context
This intelligent ErrorHandling then can be reused across all flows.
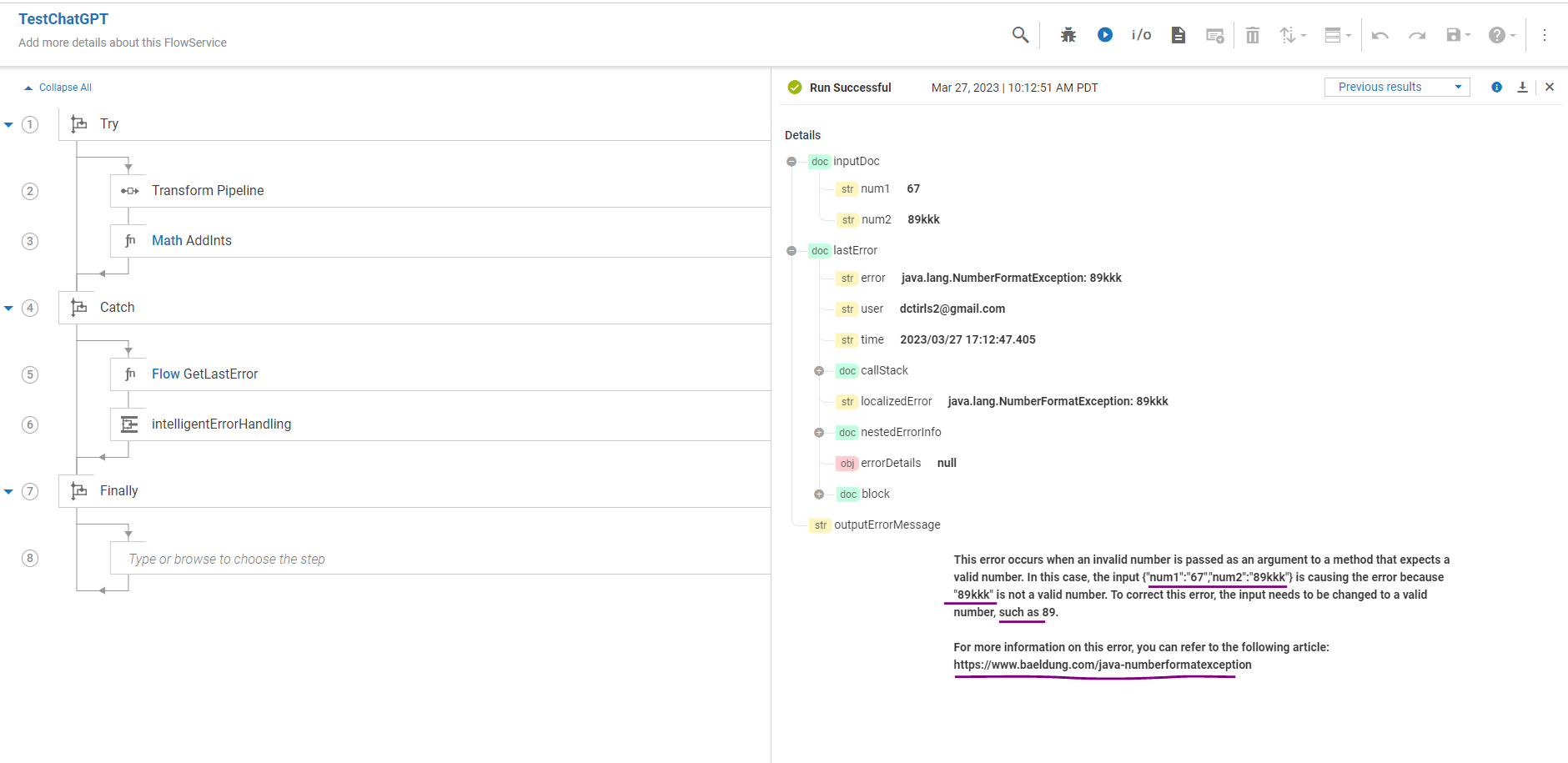
First Scenario - I am doing AddInts with one of the input (89kkk) having character at end of the number. ChatGPT is responding back which number has error and suggesting possible correct value after removing additional characters from the number.
Second Scenario - I am passing an invalid JSON format in the input. It is giving me error while trying to convert jsonStringToDocument. ChatGPT summarizing the error message and possible correct value.

Third Scenario - trying to put a file using SFTP connector. To generate an error, I am passing string as contentStream input. ChatGPT takes the input, lastError and context as input. It suggest proper error message with possible way to correct it and similar blogs or article.
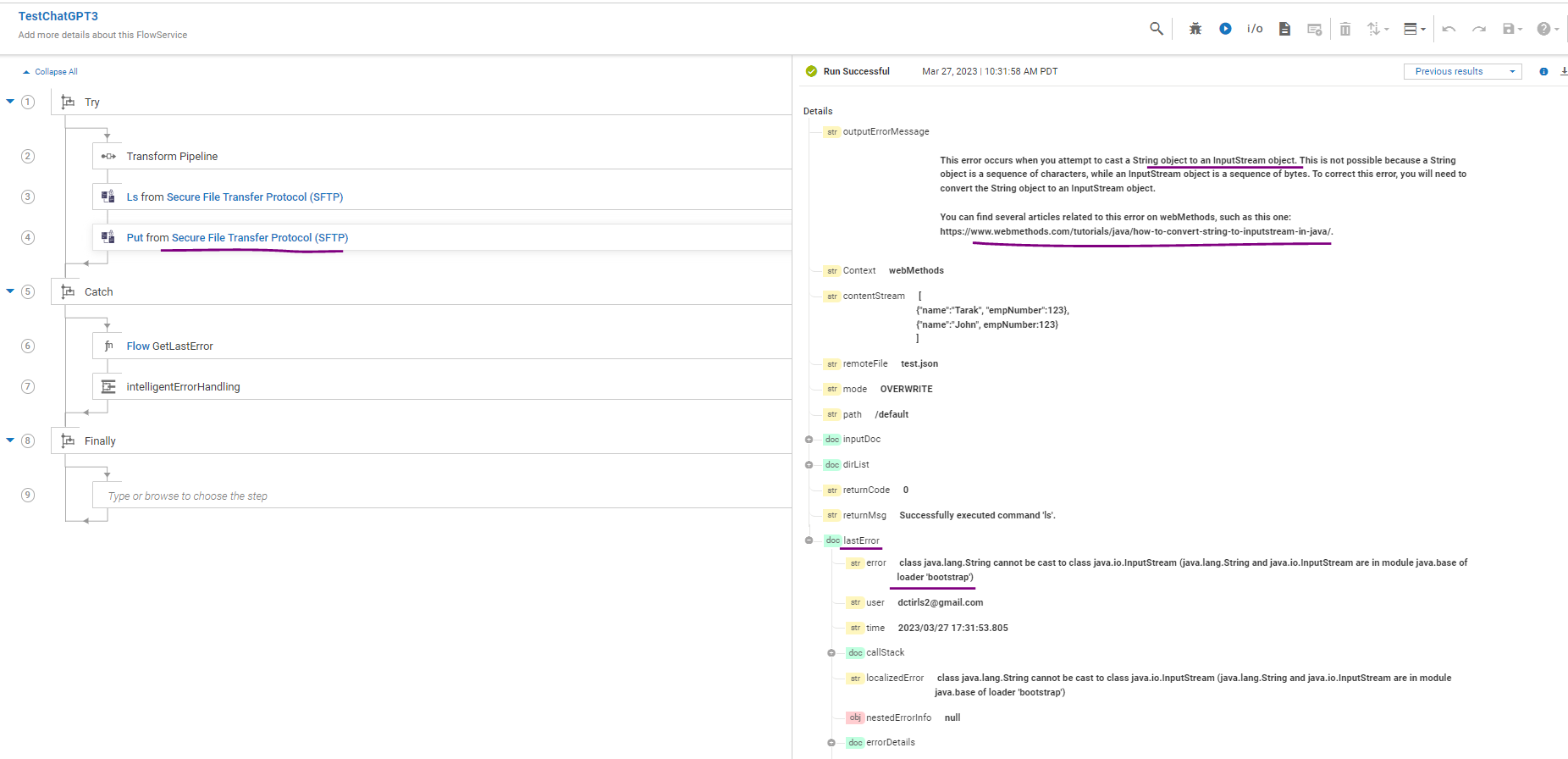
Note:- I am using free trial API key. As ChatGPT data is not current so it does not give recent article links. I think paid version of ChatGPT may be more current.