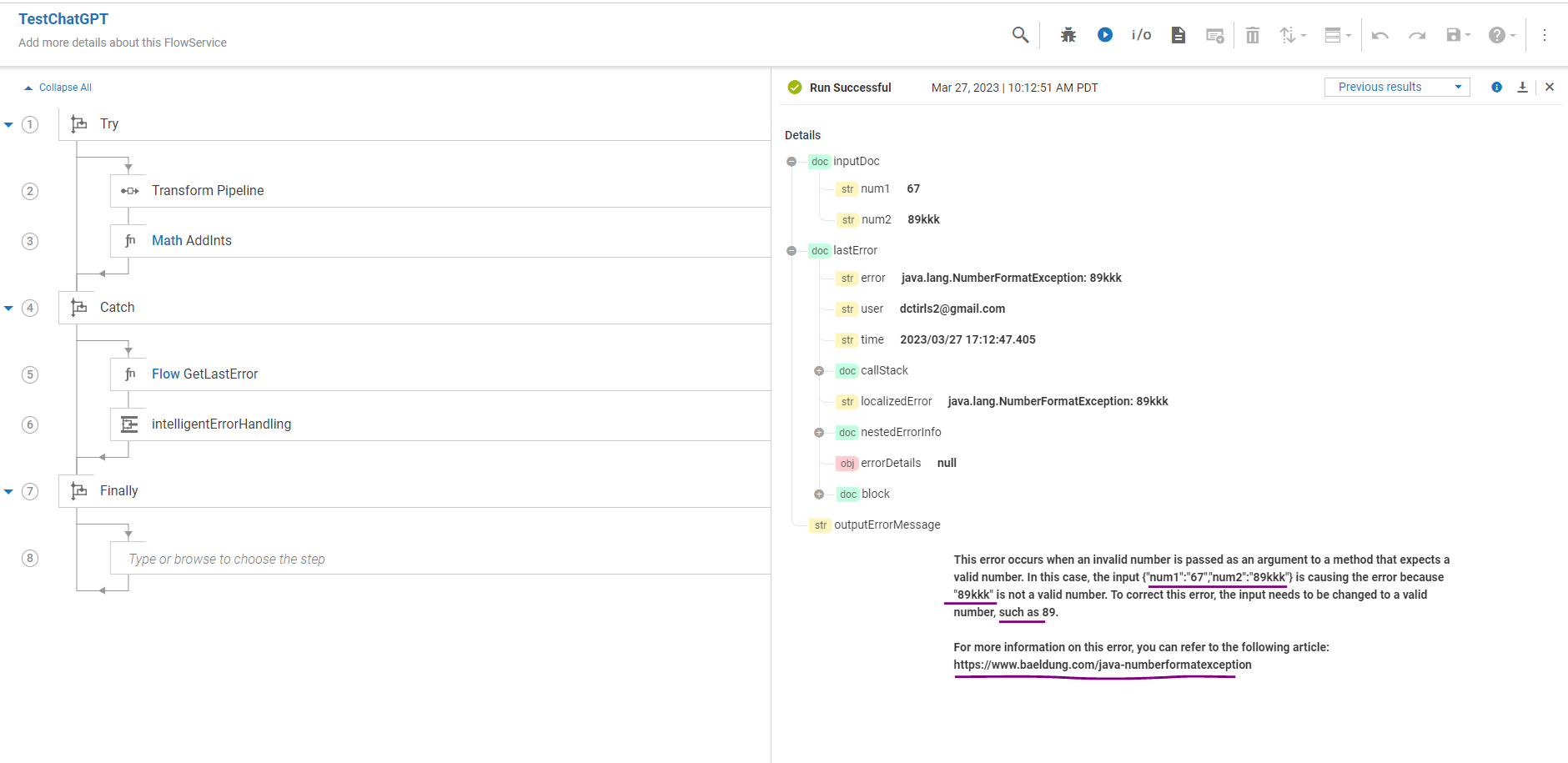
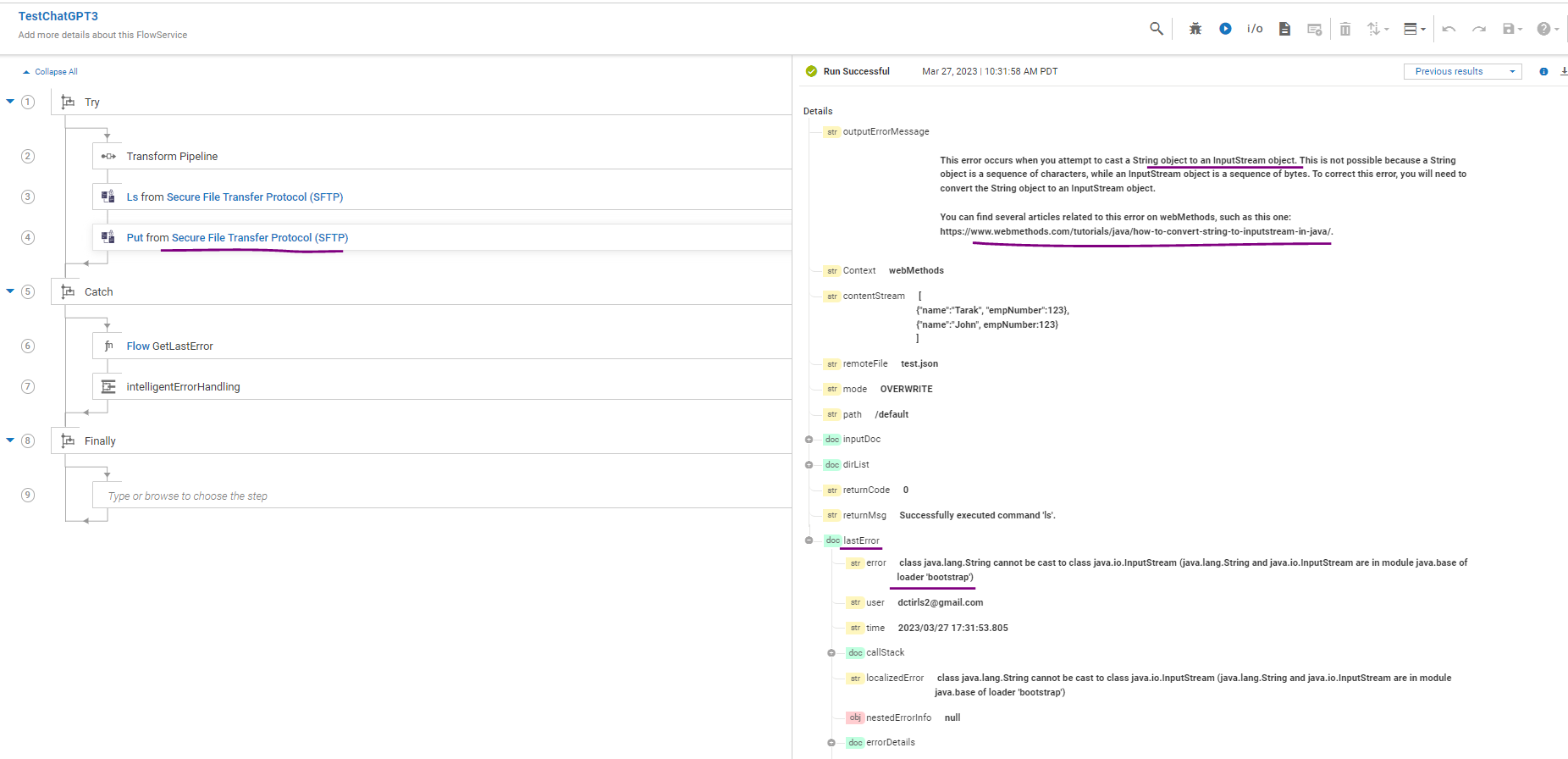
In my earlier post , I shared common flow service (intelligentErrorHandling) as one of the use case for ChatGPT. I have been exploring the possibility of further enhancing this service to customize error messages or any other system messages according to my company’s perspective. However, achieving this requires a custom trained model of ChatGPT, which needs to be fine-tuned based on specific data relevant to my company.
To accomplish this, I followed the guidelines provided in the following resource: https://platform.openai.com/docs/guides/fine-tuning.
I utilized the webMethods ChatGPT connector for the following purposes (except step #1):
- Create and upload custom data into the OpenAI organization to fine-tune the ChatGPT model.
- Create a fine-tuned model with the custom data.
- Retrieve or list the fine-tuned model to verify if the model training is completed with the custom data.
- Utilize the fine-tuned model to generate completions as needed.
1) Create and upload custom data into the OpenAI organization to fine-tune the ChatGPT model.
Created excel sheet with prompt and completion. To get better result, we need to have good amount of training data.
Then convert this data(xlsx) into jsonl format, required by ChatGPT model. This conversion done in local machine, using below command.
openai tools fine_tunes.prepare_data -f .\jsonl.xlsx
jsonl file will be like this
Now it needs to be uploaded to my OpenAI organization. I used python code to upload the test data file into my OpenAI organization.
From this output what we need is the file ID- “id”: “file-EsSFzDpXixTVWE3JYczRbSYg” for next call using webMethods ChatGPT connector.
2) Create a fine-tuned model with the custom data.
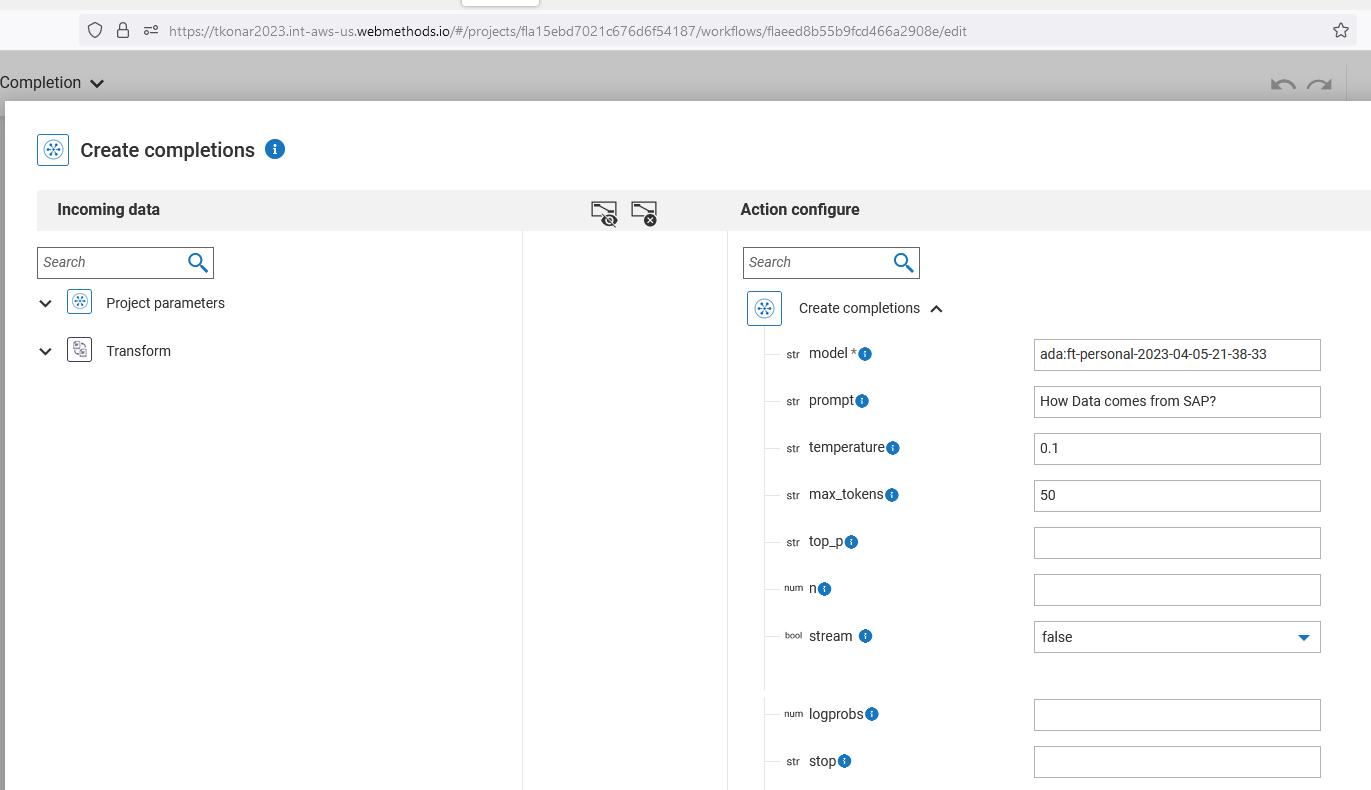
To call the OpenAI create fine-tune action from the webMethods ChatGPT connector, we need to pass the file ID from the previous step and specify the base model we want to train on the custom data. There are four base models to choose from: ada, curie, babbage, and davinci. These are different variants of the GPT (Generative Pre-trained Transformer) model architecture developed by OpenAI, and they differ in their size, power, and intended applications. Davinci is the largest and most powerful, Curie is the second-largest, Babbage is smaller but still powerful, and Ada is specifically designed for scientific applications.
I have chosen to use Ada, as I am using the free trial and this base model is less expensive to train with custom data. When checking for the same data to train Davinci, it costs 0.47 USD, while Ada only costs 0.01 USD. However, as we increase the epoch size, the cost will also increase. Epoch refers to a complete iteration of the training dataset during the model training process.
In the screenshot below, you can see that I have used 50 epochs with a batch size of 10. The learning rate is a hyperparameter that determines the step size at which the model’s weights are updated during the training process. In this case, I have used a learning rate of 0.0001.
Once it is run, in the output it will give fine tune ID (Job ID).
So this job is queued in OpenAI to run.
3) Retrieve or list the fine-tuned model to verify if the model training is completed with the custom data.
If we use the “List Fine Tune” action, it will give us the status of all the job IDs that we have run previously, including the most recent one. However, if we use the “Retrieve Fine Tune” action, we will need to pass the specific fine tune ID as an input.Here I am using retrieve fine tune action.
This job goes through 4 sages. Pending, Running, Succeeded, Failed.
As shown in the screenshot below, the initial status of the model training was “pending.” The queue number started at 9 and eventually came down to 0. The model training will begin running in a few seconds. The cost of the training will depend on the number of epochs, the base model used, and the size of the training data. In this case, the training charge was 0.03 USD.
After 1-2 mins, I again run the same workflow to check the status.
This time, You can see it is running. 18 epochs completed out of 50.
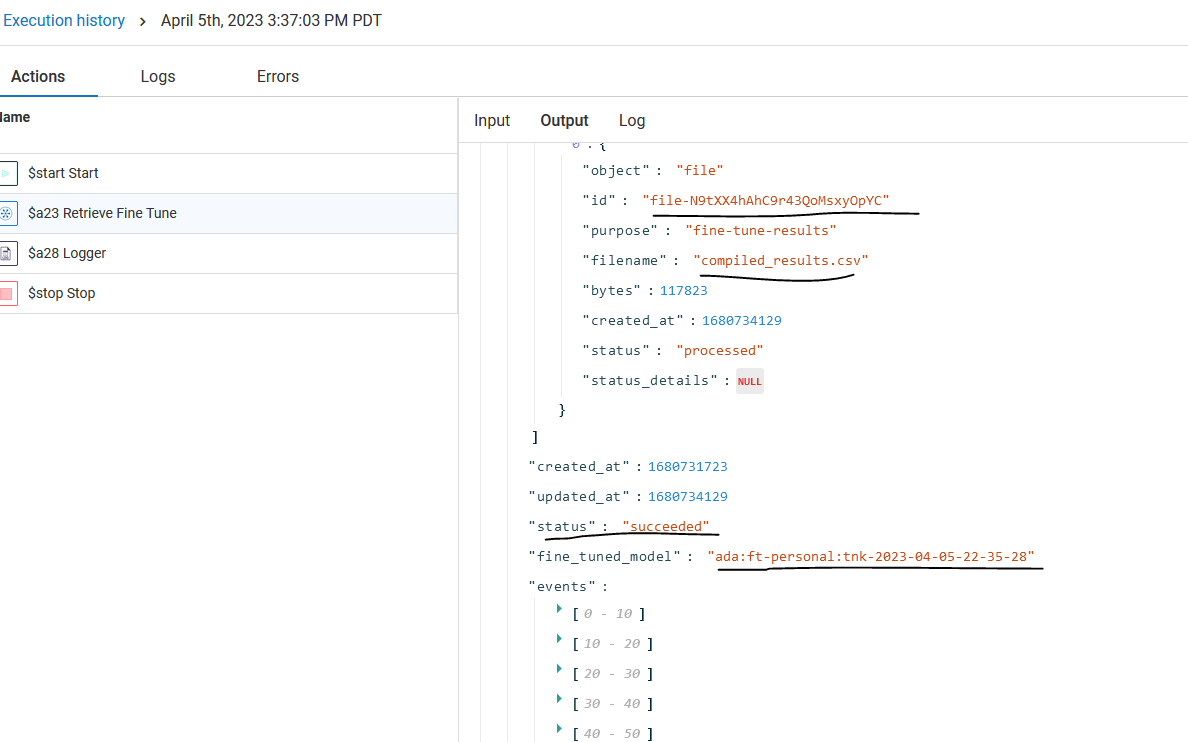
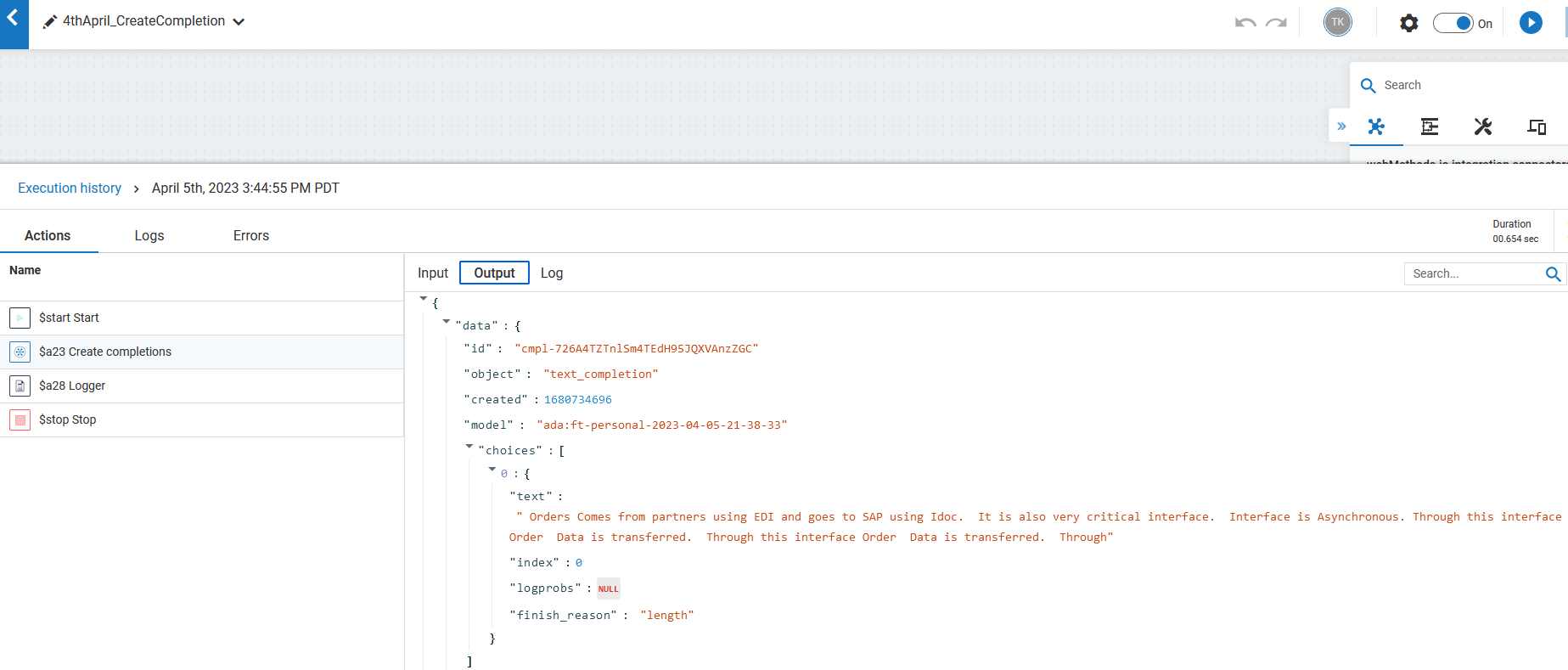
Now once training is done, status will be succeeded. In the output it will give me the fine_tuned model name , which is now trained on my custom data specific to my requirements.
On the above output, you see compiled_results.csv, that contains model training results. This file also has one ID highlighted.
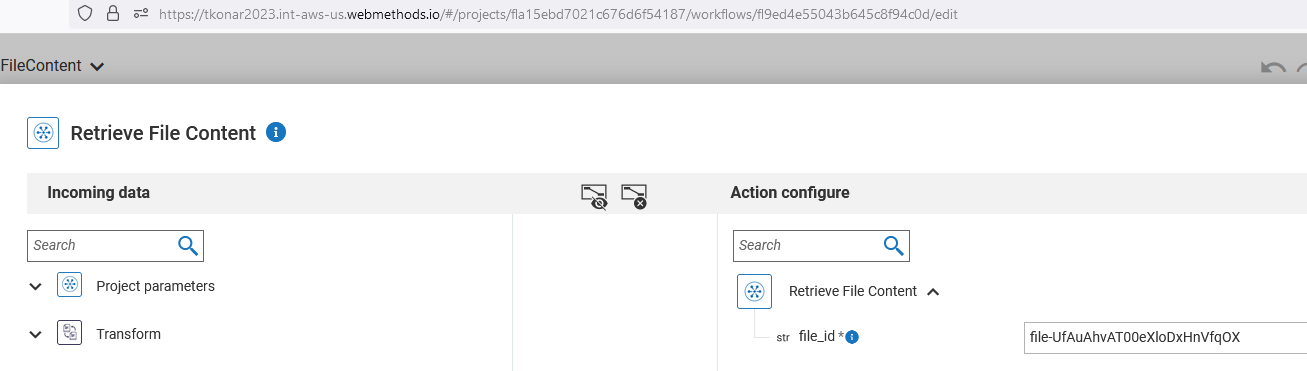
If you want to verify those training results, can use retrieve file content action of ChatGPT connector.
Here is the output
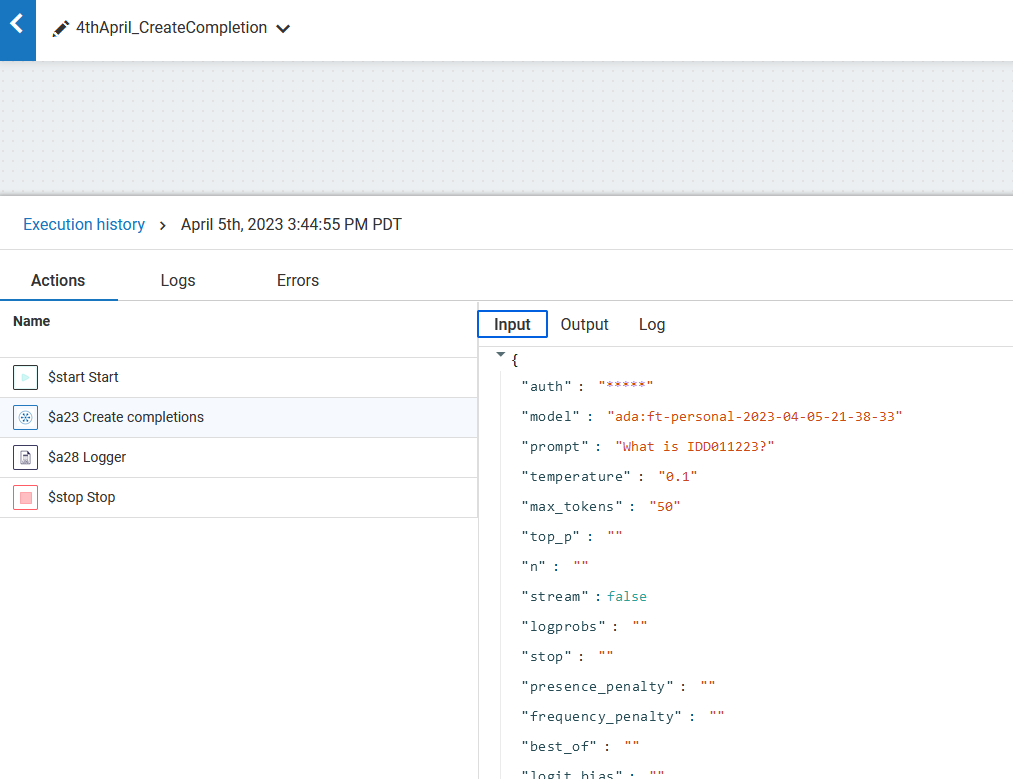
4) Utilize the fine-tuned model to generate completions as needed.
Same model tested again another input here
Using the process described above, we can create a custom-trained model by fine-tuning the ChatGPT base model with our company’s data. This fine-tuned model can then be used as an improved version for intelligent error handling.
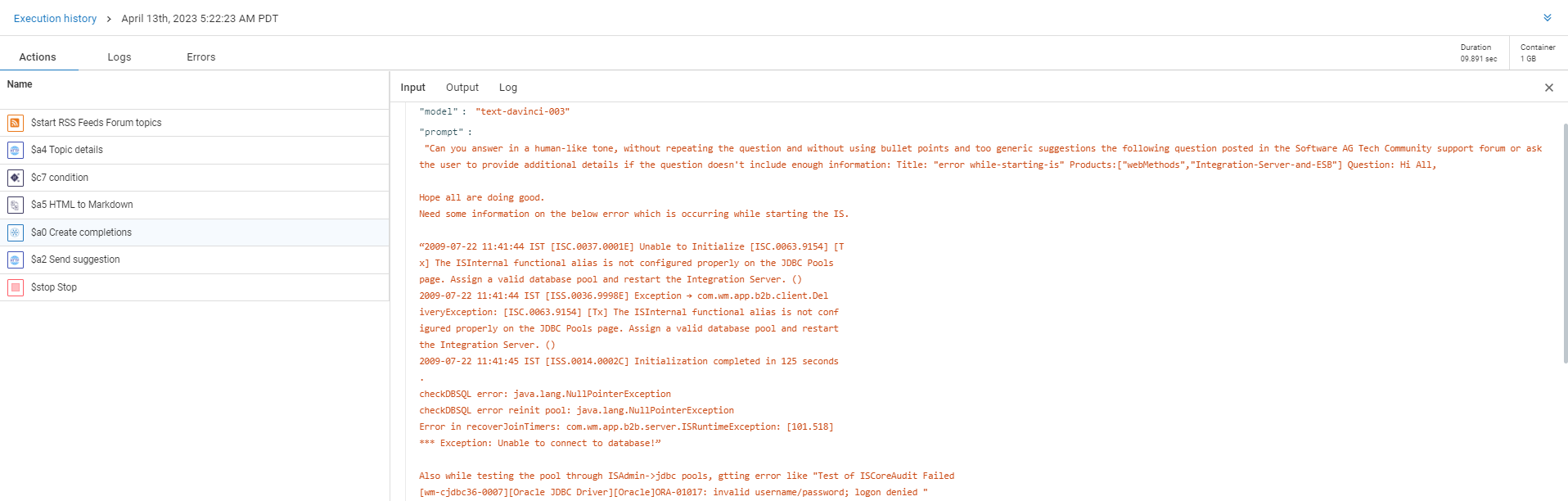
One potential use case for this approach is to train the model with all of our past incident logs. By doing so, the model can identify and pinpoint specific incidents and their resolutions within our company when a similar error occurs. This can lead to better SLA adherence and be tailored specifically to our team’s needs.
Another potential use case would be to train the model with all of the metadata for our interfaces. This would allow our development and architecture teams to search for different systems, identify what type of data is being transferred from each system, and understand the different integration patterns or data transfer mechanisms being used for a specific system.
Now, let’s consider another interesting use case where we can capture runtime data and automate all the steps mentioned earlier to train the model automatically, maybe on a daily basis or as required. We can then use this fine-tuned model, trained with our system’s current data (which could be masked transaction data or infrastructure data), and make completions based on it